はじめに
この記事はBBSakuraNetworkアドベントカレンダーの5日目です。
自分はBBSakuraでアルバイトをしている大学生です。 さくらでバイトをしていたところ気がついたら出向していて今はコアモバイルの開発に携わっています。アルバイトに出向ってあるんですね。びっくり。 今はB3なのでそろそろ大学で研究しないといけなくて焦りを感じてます。
さて、今回話すのは自分の趣味の話をします。 eBPF と言われるパケット処理のための処理技術があるのですがそれが好きで、最近はBPFを利用した高速パケット技術の手法としてXDPを追いかけています。今回はそれを始めるにはどうすればいいかをみたいな話を紹介したいと思います。
対象読者としては高速パケット処理をやりたいけど、どうすればいいかわからない!って人をターゲットにしてます。始めるときにみると手引きみたいなknowledgeを目指します(自分向けのメモぽさがあるな) 書かない話としてはパケット高速化についての細かい手法は話しません。(むしろ良さそうなのがあれば教えて欲しい)
とは言っても界隈では有名な yunazunoさんやhigebuさん、YutaroHayakawaさん、がいい感じの記事や話をしているので(興味を持ったらこの人たちをウォッチすべきです!)そちらを見ておけば大体入門できるんですが、とはいえ自分なりに基本的な導入とはじめにつまづいた事とか最近の界隈の話をしようかなと思います。
雑にXDPを理解するための概要
XDP(eXpressDataPath)はLinuxカーネルで動く高パフォーマンスのプログラマブルデータパスです。 sk_buffというデータ構造の割り当てをする前に直接データをBPFを使ってカーネルランドで処理をすることで高速な通信を実現しています。
どれくらい早いかというとこんな感じです。

cf. https://people.netfilter.org/hawk/presentations/xdp2016/xdp_intro_and_use_cases_sep2016.pdf
XDP自体の詳細はリンク先の論文を参照してください。
以下の画像は論文より抜粋した画像です。
具体的な処理の場所はXDPと書いているところで、他に関係するところは基本的に水色の部分がXDPに関係してきます。

確かにカーネルランドにあるデバイスドライバーで真っ先にパケットを受けているというのがわかると思います。
BPFとは
BPF(BerkeleyPacketFilter)というパケットフィルタ機構です。これはカーネルランドで高速にパケットを処理することができるコアの機構です。今回のXDPのコアでも利用されている機構でもあります。
この部分は誤解を恐れずに説明するとパケット処理専用のCPUをカーネルランドでエミュレートしたようなもので、MIPSに近い命令セットを持ったVMが存在しています。これらはtcpdumpなどで現在も使われている機能です。
近年ではこれらはLinuxにおいて拡張されてe(xtend)BPFと呼ばれるようになり、パケットのみならずSeccompなどのシステム間のセキュリティ機構として使われるようになり、またトレーサーとして使われています。
今回はネットワークにおいての利用の話をメインでしていきます。実行のイメージとしてはこのような形になるはずです
eBPF Map
eBPFMapというのはBPFがユーザーランド等とやりとりしたい時に使えるテンポラリーなデータ領域のことを指します。平たく説明すると共有で使えるKeyValueなテーブルです。
イメージとしてはこのような感じです。
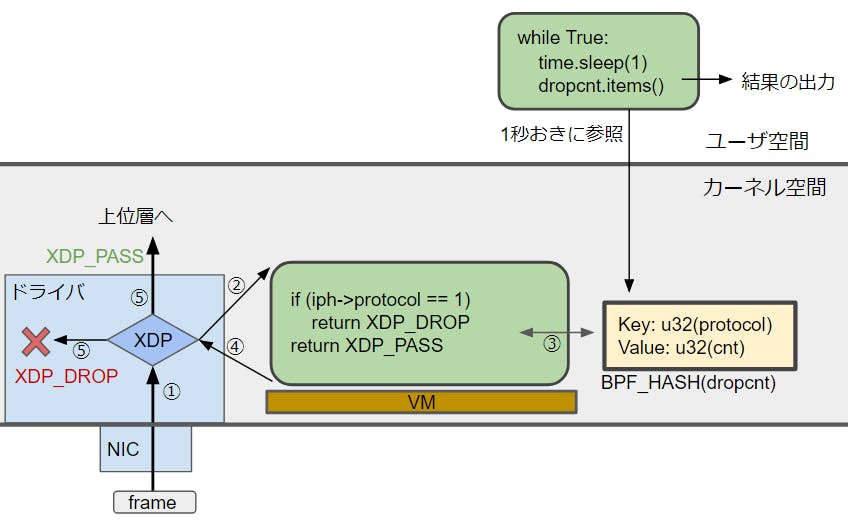 cf. https://qiita.com/sg-matsumoto/items/8194320db32d4d8f7a16
cf. https://qiita.com/sg-matsumoto/items/8194320db32d4d8f7a16
そこにはeBPFがeBPFMapに書き込んでユーザーランド側でその情報を得たり、その逆でユーザーランドからそこに書き込んだり、またeBPFがeBPFにパケット情報などを処理を渡すこともできます。 XDPもカーネルランドで動作していることからユーザーランドとやり取りすることができません。そこでBPFの機能となってるeBPFMapを使ってユーザーランドとやり取りをします。具体的なユースケースはNFVやLBのサービスの登録などで利活用されます。
Generic XDP
パフォーマンス上の理由から、XDPの処理はsk_buff(linuxのネットワークスタックに使われるソケットバッファー)が割り当てられる前にデバイスドライバーから直接呼び出されます。このことは先程のXDPのアーキテクチャの画像から理解できるとおもいますが、ということはXDPの動作にはデバイスドライバー側でのサポート対応が必須ということが言えます。
しかしながらまだまだ未対応のNICドライバーが殆どです。そこでXDPをどの環境でも使えるGenericXDPというモノがlinux kernel4.12に導入されました。速度は出ませんが開発等では非常に有用です。
利活用例
facebook: katran
facebookが社内のデータセンターで利活用しているL4LBです。以前はIPVSを利用していたのですが、自作するようになりました。
特出してるところはL4LB部分で以下の事柄です。
- XDPを使って実装されていて高速に動かしている
- DSR限定でkatranは動く
- RSSに対して最適化されてる
- マルチqueue受信をしていて、XDPの機能でCPU間で負荷を均一に分散させることを行ってる
lineでも L4LBを自作し同じようなことをしていますのでそちらも合わせてみると良さそうです(リンクは後述する)
cilium
これはサービスやコンテナ間の通信をセキュアかつ負荷分散を高速にするために作られたフレームワークです。k8sなどのオーケストレーション上で動かすことを想定しています。
cloudflare: L4Drop, XDP DDoS Mitigation
cloudflare が行っているもので、XDPを使ってDDoS緩和をしています。
方針としてはXDPを後述するtail_callという方法で多段におきます。そしてサンプルを抽出し、解析をして
その結果をgatebot と呼ばれるルール注入装置に渡してdropするかを判断するルールをXDPに注入します。
- cf. https://netdevconf.info/2.1/papers/Gilberto_Bertin_XDP_in_practice.pdf
 - https://blog.cloudflare.com/l4drop-xdp-ebpf-based-ddos-mitigations/
- https://blog.cloudflare.com/l4drop-xdp-ebpf-based-ddos-mitigations/
これは実際にプロダクションとして稼働していて、毎秒800万パケット以上をドロップを一台で達成しているそうです。
ミクシィ、Static NAT
Global <-> privateの静的NATに利用してるらしい cplaneはgRPCで動いているコントロールサーバーがある。
12Mppsぐらい処理ができる。またパケットのコレクターとしても利用している。 ハマった課題については大規模なバックボーンを持たないと起きないことが書いていて一見の価値があります。
interop tokyo, end.ac
interop tokyoの2019で展示されたSRv6のファンクションにXDPをinterfaceに使ったAF_XDPを利用したものがあります。
これはAM -> midle node(ex. LB, DPI, mirroring)→SRv6 decap(DX4)→application のmidle nodeが IPv6が使えない場合を解決できるFunctionで、AMの場合はmidle nodeがv6を理解できて、その場合だとSRHを外さなくて転送だけであれば解釈する部分が事足ります。
しかし、v4ということはSRHを外す必要が出てきます。 そこで具体的には End.ACのノードに着信したらSRHをキャッシュして、outerpacketを外し、その時にinner packetがv4の時にToSにあるキーを入れておいて戻ってきたらそれを元にlookupするという方針にします。
これによってSRHは外してしまったが、元のパケットとSRHを照合できる。という便利なファンクションです。
ちなみに RFCを見るとintarop公開時の時の End.AC からEnd.AT に変わったみたいです。なんでこういう名前になったんだろう・・・
後述するAF_XDPをやる際にはこれを参考にするといいかもしれないです。
と、このようにすでにXDPの技術は多くのところで利活用されています。
XDPを用いたのパケット読み込み例
このセクションでは前述したXDPの仕組みや周辺はどのようにプログラムを書かれて動くのかというのを紹介したいと思います。
以降で説明するマシーン構成はclient, serverという2つのマシーンが通信ができるという前提です。またclientにはBCC(BPF Compiler Collection) + pythonが入っている前提です。
雑にこの辺(INSTALL.md)を見てinstallすると試せると思います
BCC(BPF Compiler Collection)はユーザランドで動作するツール群です。XDPプログラムの読み込みやカーネルランド側の操作を補助しつつ、Pythonバインディングが用意されているので、カーネルで動作するXDPプログラムはCで書きながらもユーザランド側の高度なマネジメントをpythonで書くということが可能になります。
以下は通信パケットがPort 8080の受送信に関わってる場合にDROPする例です。
serverではpython -m SimpleHTTPServer 8080で適当な8080で動くhttpサービスを立ち上げつつ、clientではwgetなどができるかまずは確認をして、その後、以下のソースのコードをアタッチしましょう。
#define KBUILD_MODNAME "foo" #include <uapi/linux/bpf.h> #include <linux/in.h> #include <linux/if_ether.h> #include <linux/if_packet.h> #include <linux/ip.h> int xdp_prog(struct xdp_md *ctx) { /* * xdp_mdにあるメンバーから取得するべきは以下の2つ * data: パケットの先頭ポインタ * data_end: パケットの終端ポインタ * dataの先頭なので大体の場合はethを初期値では読むことができます */ void* data = (void*)(long)ctx->data; void* data_end = (void*)(long)ctx->data_end; struct ethhdr *eth = data; // 次のパケットを読むためのオフセット(ethを読んだ後なので次はipヘッターの先頭を参照することになる) uint64_t nh_off = 0; nh_off = sizeof(struct ethhdr); /* * 以下の条件はdata+nh_off + 1がdata_endの範囲を超えていないのかをチェックしてます * 今回の場合は次のipヘッター領域を邪魔していないのかを見ています * もしこれを怠った場合、eBPF verifierにエラーを吐かれてアタッチができないハマりポイントなので要注意 * */ if (data + nh_off + 1 > data_end){ return XDP_PASS; } // ipプロトコルを取得 uint16_t h_proto; h_proto = eth->h_proto; // プロトコルがipv4であれば if (h_proto == htons(ETH_P_IP)){ // data + ethの領域分を飛ばしてipヘッター部分を読み込む // 領域が出ていないのかチェック struct iphdr *iph = data + nh_off; if (iph + 1 > data_end){ return XDP_PASS; } // tcpかudpかのプロトコル取得 // iphdr分読み飛ばすためにオフセットを入れる(eth + iph) h_proto = iph->protocol; nh_off += sizeof(struct iphdr); }else{ // v4以外ならばパケットをドロップしないで通過させます return XDP_PASS; } //tcpでやりとりしているか if(h_proto == IPPROTO_TCP){ struct tcphdr *tcph = data + nh_off; // 領域を見る if (data + nh_off + sizeof(struct tcphdr) > data_end){ return XDP_PASS } // ポートの取得 uint16_t dst_port; uint16_t src_port; src_port = tcph->source; dst_port = tcph->dest // 8080ならドロップ if(dst_port == 8080 || src_port == 8080){ return XDP_DROP; } } // v4以外ならばパケットをドロップしないで通過させます return XDP_PASS; }
アタッチするための共通になるコードを以下に示します。
python loader.py ens3のような感じで動かす事ができます。
from bcc import BPF import pyroute2 import time import sys device = sys.argv[1] mode = BPF.XDP # generic xdpとの切り替えはflag=2に変更することで行うことができます。 # flags = 2 # XDP_FLAGS_SKB_MODE flags = 0 # load BPF program b = BPF(src_file="./function.c", cflags=["-w"]) fn = b.load_func("xdp_prog", mode) b.attach_xdp(device, fn, flags) print("CTRL+C to stop") while 1: try: time.sleep(1) except KeyboardInterrupt: print("Removing filter from device") b.remove_xdp(device, flags) break
パケットの書き「換える」例
先ほどのコードでどのようにXDPでパケットを扱えば良いかが雰囲気としてわかったと思います。 簡略化のためにコアの必要な部分のみ載せます。以下のコードはポートを書き換える例です。
struct tcphdr *tcph = data + nh_off; if (data + nh_off + sizeof(struct tcphdr) > data_end){ return XDP_DROP; } tcph->dest = newdest;
実際に書き換えたあとは必要に応じてchecksumを再計算します。
また、memcpyを使っても問題ありません。
パケットを書き「加える」例
以下のコードはIPIP(IPv4)encapする例です。
このコードではipv4_csum_inlineとget_macaddr*という関数はipチェックサムを計算する関数と使用したい宛先のmacaddressを読み込む関数です。これらはライブラリ中に定義されておらず適当な自作関数であることに注意してください。
以下のコードで注目すべきは bpf_xdp_adjust_headという関数です。これはXDPプログラム中でパケットの取り扱ってるxdp_md構造体の先頭領域を広げる事ができる関数です。これによってxdpで受け取ったパケットを書き加えたり、外したりできます。
今回の場合はIPv4のencapを行いたいのでipヘッターの領域分を広げる必要があります。
注意点としては先頭領域の拡張なので以下の画像のようにEthhdrを移動した上で新しくIPhdr分を書き加えてあげる必要があります。

static inline int encaption_IPIP_v4(struct xdp_md *xdp) { struct ethhdr *new_eth; struct ethhdr *old_eth; struct iphdr *new_iph; struct iphdr *old_iph; uint64_t csum = 0; if(bpf_xdp_adjust_head(xdp, 0 - (int)sizeof(struct iphdr))){ return 0; } void* data = (void*)(long)xdp->data; void* data_end = (void*)(long)xdp->data_end; new_eth = data; new_iph = data + sizeof(struct ethhdr); old_eth = data + sizeof(struct iphdr); old_iph = data + sizeof(struct iphdr) + sizeof(struct ethhdr); if (new_eth + 1 > data_end || old_eth + 1 > data_end || new_iph + 1 > data_end || old_iph + 1 > data_end){ return 0; } uint16_t payload_len; payload_len = ntohs(old_iph->tot_len); uint8_t mac_address[6] = get_macaddr(); __builtin_memcpy(new_eth->h_source, old_eth->h_dest, sizeof(new_eth->h_source)); __builtin_memcpy(new_eth->h_dest, mac_address, 6); new_eth->h_proto = htons(ETH_P_IP); //IPIPにencapしたパケットの設定をする new_iph->version = 4; new_iph->ihl = sizeof(*new_iph) >> 2; new_iph->frag_off = 0; new_iph->protocol = IPPROTO_IPIP; new_iph->check = 0; new_iph->tos = 0; new_iph->tot_len = htons(payload_len + sizeof(*new_iph)); new_iph->saddr = get_macaddr_s(); new_iph->daddr = get_macaddr_d(); new_iph->ttl = 8; // ip checksumを計算する ipv4_csum_inline(new_iph, &csum); new_iph->check = csum; return 1; }
XDP周りでの引っかかりポイントと知見
XDPを使うにあたって2段階のチェックされるタイミングがあります。 1つはコンパイル時。2つめがeBPFVerifierと呼ばれるプログラムチェック機構です。 1つ目は大体構文とライブラリのパスが通っておらず失敗するパターンなので多くのエンジニアに解決可能な問題のことが多いですので割愛します。
しかし問題2つ目に挙げたeBPF Verifierです。これは安全ではないコードを実行させないというものなのですが、どうして安全ではないかがわかりにくく、デバックするのにあたっても非常に難しいです。 具体的にはXDPのプログラムをNICにアタッチすらさせてもらえず貧弱なエラーメッセージがただ出てくるのみとなっております。正直初学者には非常に厳しいです。
非常に慣れず苦労したのでここではそれについての簡単な知見を書き残したいと思います。
まず、XDPのコードは読んでいるとわかるのですがいくつかのイディオムがあります。
例えば、以下のコードは先程示したコードからの抜粋ですが iph + 1 > data_end という比較をしています。これはiphの先頭から次の領域が存在してるかのチェックをしていて、これによって無効な領域に飛んでいないかをチェックしています。これを怠った場合、安全ではないとVerifierに怒られてしまいます。
struct iphdr *iph = data + nh_off; if (iph + 1 > data_end){ return XDP_PASS; }
他にもbuiltin_memcpyを使わなくてならないという制約があります。eBPFはeBPF組み込みの関数しか呼び出すことができないという制約があるので、さもないと謎のエラーとヒントを出してアタッチができないという状態が起きてしまいます。
__builtin_memcpy(tcph->check, newcheck, sizeof(uint16_t));
このようにいくつかのイディオムが存在していて、BPF特有の書き方が存在します。同じようにmemsetなどもbuiltinで使い、関数はinline展開が基本です。そのため自作の関数はalways_inlineなどでinline展開を強制する必要があります。
なので、個人的な意見としては慣れない間は極力後述するサンプルコード群になるべく近いベーシックなコードを書くのが変な失敗を踏み抜かないコツです。
他にもどんなバイトコードを吐くのかを見るのも非常に得策です。 その時は以下のように自身でclangでコンパイルしてみて、その上でそれをobjdumpしてみるという手があります。最適化によってバイトコードが簡約されるというのとbccとは環境が異なるところが存在するのでそこには気をつけましょう。
clang -O2 -Wall -target bpf -c xdp_drop.c -o xdp_drop.o llvm-objdump -S -no-show-raw-insn xdp_drop.o
また、アタッチしたあとにうまくいかない場合があると思います。そんな時は「そもそも条件分岐に来ているのだろうか?」と実際の挙動が気になるのではないでしょうか。
その時はbpf_trace_printkとeBPF mapを使う方法があります。残念ながらXDPやBPFにはDebuggerのような高度なものはないのでどちらも実質的にはprintfデバッグです。
前者のbpf_trace_printkは本当に用途がただのprintfデバッグゆえ説明することがあまりないので割愛しますが、後者のeBPFmapを使うケースとしてはデバッグする時にステートがほしい時やデータを計測して整形したい時などに使いやすいと考えます。理由としてはeBPFmapはbccを通じてデータを定期的に取得することができて、一度テーブルに書き込むような状態になるのでステートを持たすことができます。
以下に簡易的な例を示します。このコードの場合行き先アドレスが8080の場合8080をindexにしている値をインクリメントすることができます。 これに他の条件によって値を変化させるなどして使います。ただ実際は本質的にはprintfデバッグであることはどちらも変わらないのでお好みで使うといいと思います。
BPF_HASH(counter_table, uint32_t, uint16_t); int packet_counter(struct xdp_md *ctx) { void* data_end = (void*)(long)ctx->data_end; void* data = (void*)(long)ctx->data; struct ethhdr *eth = data; uint16_t *value; uint16_t zero = 0; uint16_t h_proto; uint16_t dest_port; uint32_t index; if (ethhdr + 1 > data_end){ return XDP_PASS; } h_proto = eth->h_proto; if (h_proto == htons(ETH_P_IP)) { h_proto = get_ip_proto(data, data_end); if (h_proto == IPPROTO_TCP) { dest_port = get_dest_port(data, nh_off, data_end); if (dest_port == 8080) { index = (uint32_t)dest_port; value = counter_table.lookup_or_init(&index, &zero); (*value) += 1; } } } return XDP_PASS; }
また bpftoolと呼ばれるツールを利用して動作中の eBPF の情報を確認するというのも有効でしょう。
実行中の見るときはjitが邪魔とかそういう時もあると思いますのでその辺に注意。 ちなみには今後は自動でjitがディフォルトで有効になります。
ちなみにプロダクションでXDPを使ってるfacebook曰く JIT is your friend というようにjitは有効にした方が高速です
cf. http://vger.kernel.org/lpc_net2018_talks/LPC_XDP_Shirokov_v2.pdf

XDPを取り巻く環境
対応nic
XDPはソフトウェアレベルで基本動くのですが、ドライバーのサポートによってhardwareでオフロード(ハードウェア動作)をさせることができるというのがあります。 有名なものだとMellanoxのmlx4,5シリーズがあります。これらはdropとTXにそのままreturnするというものをサポートしています。 かなり値段としては高いのですが、intelのnicドライバーixgbeというものが対応しているのでIntelのnicでアクセスするという方法を使うと安く済みそうです。 また、cloud基盤等で動かす場合はvirtio-netが対応してるのでVMでも使うことができるのでサービスメッシュやSR-IOVなどでも利活用することが可能で嬉しいです
ただvirtioはクセがあり、kvmで立てる際はqueues=vcpu*2, vectors=queues*2 + 2, -mq=on (cf. https://www.linux-kvm.org/page/Multiqueue ) でなおかつ
root@xdptest1:~# ethtool -g eth0 Ring parameters for eth0: Pre-set maximums: RX: 1024 RX Mini: 0 RX Jumbo: 0 TX: 1024 Current hardware settings: RX: 1024 RX Mini: 0 RX Jumbo: 0 TX: 1024
1024以上となるようにしなくてはいけません。 もしならなければ、https://github.com/qemu/qemu/blob/36609b4fa36f0ac934874371874416f7533a5408/hw/net/virtio-net.c#L52 のsizeが1026になるように書き換えてビルドしてあげる必要があります。
BPFのプログラムのアタッチについて
BPFを利用する際に netlink経由からアタッチする場合と iproute2経由 と bcc経由で実行するというのがあります。
この時実はアタッチする構成やローダーによって利用可能か機能や仕組みや意味論が変わっている場合があります。
よく知られているのは inner map の互換性は iproute2や bcc にはないということです。
誤解を恐れずにいうとinner map とは KVである ebpf map でbyte型のようなアトミックなデータだけではなく、リレーショナルさせる技術のことです。これは現状netlink経由のローダーでしか利用できません。
しかし、netlinkは簡単にアタッチできるようなサンプルが少ないの玉に傷です。iproute2やbccで普通にパケット処理をする分に事足りますのでこちらで入門すると良いと思います。
AF_XDP
AF_XDPと呼ばれる、XDPの高速処理な部分を活かしながらもBPF特有の書き方の難しさを解決した仕組みで、カーネルバイパスする機能です。アプローチとしてはnetmapに非常に似ています。以下の画像はOVSからの引用ですが、雰囲気が伝わると思います
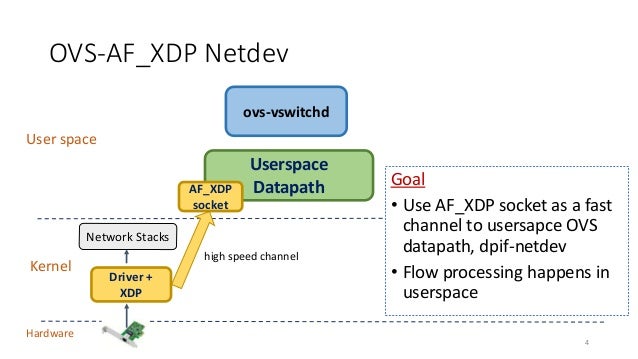
DPDKのアプローチとしてはポーリングし続ける方式なのですがそこへの利用もされています。 https://www.dpdk.org/wp-content/uploads/sites/35/2018/10/pm-06-DPDK-PMD-for-AF_XDP.pdf
最近のテクニカルな部分の話
tailcall
- cf. https://lwn.net/Articles/645169/
- eBPFにはtailcallという実行中のBPFプログラムからあるBPFプログラムにジャンプするということができます。
- ユースケースとしてはプログラムの整合性を保ったまま別の独立のプログラムを連携させたり、現状のeBPFの最大命令数は4096個であるためにプログラムの巨大化に対応するということが可能になります。
- tail callの面白いのはこれのjumpの先を決定するためにebpf mapをルックアップしてて,つまりユーザー空間側mapを書き換えるとで飛ばす場所を変更できるということが簡単にできるというのがあります。
- ちなみにkernel v5.3において100万の命令を利用可能できるようにしたいという言及があるために、プログラムの巨大化での利用は今後はしなくても良くなる可能性があります。
- cf. https://lwn.net/Articles/794934/
- 最近では Chain-calling と言われる概念が提案されていて、自分でそのtailcallsのmapを制御しなくてもいいようにルールベースで実行するフローが提案されています

global 変数のサポート
今まではglobal領域で変数や定数として使いたい場合は eBPFmap を利用して扱っていたのですがそれを毎回書くのは正直オペレーションとして邪魔でしかないので、そこで内部的に長さ1のmapを利用して隠蔽して普通の変数として利用できるようになりました (おそらくBPF_PSEUDO_MAP_FDを使ってると思うんですが、さらっと読んだだけなので間違えたらすいません。)
ちなみに定数のみのアプローチであればBPFプログラム内の定数を変更する際にアタッチ前に直接BTFのバイナリを書き換える方法もあります。
bpf trampoline
retpolineと呼ばれる間接呼び出しをROPで置き換える投機的実行に関する脆弱性の対策方法がありますが、しかしそれが元でbpfをkernelでコールする時に分岐予測が効かないので速度が落ちてしまうという問題がありました。 そこでそれを回避することで従来と比べてeBPFの呼び出しを高速に利用できるというものが提案されました。(つまりXDPの高速化につながります!)
cf. https://lore.kernel.org/bpf/20191102220025.2475981-4-ast@kernel.org/
さらに最近提案されたのはそのアイディアはそのままでは使いにくいので、bpfdispatcher と呼ばれるの概念を導入して xdp_call.h でXDPでも利用しやすくされたものを出てきています。今後もパフォーマンスが上がっていくのが目に見えるようで嬉しいですね。
XDPを始めるのに見ると良いリンク群
見出し通りですが、それだけ貼っても仕方ないので個人の感想を段落にして書いてます。
- Linuxカーネルの新機能 XDP (eXpress Data Path) を触ってみる
- 貴重な日本語記事
- ただドロップするだけのコードがある。適当に動かすのに良い。bccで行われている
- BPF_PROG_TEST_RUNでXDPプログラムの挙動をテストする
- XDPのユニットテストコードを書くのに参考になる
- xdp-tutorial
- linux
- Cilium, BPF and XDP Reference Guide
- BPF: A Tour of Program Types
- オラクルが描いてるBPF及びXDPの入門。
- 連載してるみたいな感じで続いていて、これをガッツリ読むと結構詳しくなる。BPFがちょっとわかって英語がちゃんと読める人間はこっちから入門した方がいいかも。
- katran
- 先ほども紹介したが、facebookのL4LB.これの学ぶべき点は開発している方法が良かったです。どうやってビルドしてるかみたいなのが開発に参考になりました。
- LINEの独自LBaaSを支えるソフトウェアエンジニアリング
- ソフトウェアでのパケット処理あれこれ〜何故我々はロードバランサを自作するに至ったのか〜
- XDPの最新動向とLINEにおける取り組み事例 / Recent updates on XDP
- lineが作ってる XDP を利用したL4LBの話。XDPの具体的な活用法が書いてる貴重な日本語資料。自動化されたテスト環境にTReXを使ってunit testに
BPF_PROG_TEST_RUNを使ってることを話してる。また監視についても言及しているので本格的に使うなら参考にすると良いです。 - 最近の困りごとについては非常にそ、そうか・・・みたいな気持ちになるのでみておくと良さそう。早くmapのbulk insert/updateぽいのが入るといいですね・・・
- lineが作ってる XDP を利用したL4LBの話。XDPの具体的な活用法が書いてる貴重な日本語資料。自動化されたテスト環境にTReXを使ってunit testに
- goxdp
- netlinkを内部で利用してるよいexample.
- プログラマブルに初めから用意されてるのでここから改造すると良い。
- 後日公開予定の趣味で自作しているSRv6ファンクションのサブセットはこれを参考に作っている。(本当はこっちを書く予定だったが。。。進捗が無で書けなかった)
- goなのでgrpcの親和性が高くておすすめです。
まとめ
雑にいろいろ書いてきましたが、XDPは今までのパケット処理のつらさが減るという部分もあります。linuxのヘッター類、つまり我々がず〜っと利活用してきたプロトコルスタックに使われてた資産が使えるので構造体などのサブセットを自前で頑張らずとも用意されていたり。 他にもlinuxのネットワークスタックとシームレスに作られていて(skbuffはxdpbuffから作られてる)、 例えばarpパケットの場合はlinuxにpassしてあげることでarp tableの管理をlinux側に丸投げするということが可能で、取り出す場合はfiblookupを使うだけでfibがわかる手軽さです。これは他のパケット高速処理系には真似ができないと思います。
しかしトレードオフもあり、BPFのチェックや、あまりにニッチすぎることをするとドライバーによって未実装の機能があったりしてつらい場合もあり、clangのバージョンを雑に上げたらバグるとか特にkernelLandで動かすのでバグる時のデバッグがつらいなどがあります。
もちろん他の高速パケット処理手法も似たり寄ったりですが、実はちょっとした入門だけなら敷居が低いということが伝わると嬉しいです。
自分でパケットを投げれるというのは非常に楽しいのでぜひやってみてください!! (間違いがあればそっと連絡をくれると助かります!)